Brief recap: I’ve been using Last.fm to keep track of the music I listen to for over ten years. This has provided me with the oportunity to inspect, analyze and visualize my data in search for patterns and interesting trends. Some of the previous work includes: artists wordclods, map-masked artist wordclouds, polar-plot playcounts over time of day, and artists’ transitions networks.
After playing a bit more with my last.fm dataset, I realized I hadn’t really found any good way to show artists’ playcounts over time. All of the other visualizations I had done before are static snapshots of agregated playcounts, so I became interested in figuring out a way to show the temporal information of the data. This, however, required some thinking and time to develop, as it required compressing a lot of temporal information into a single panel.
Initially, I was thinking of doing some simple scatterplots with dots to mark the times at which artists had been played over time. This wasn’t too bad but the dots overlapped heavily and were not very appealing. After a couple of tests, I figured doing a thin line on every play, with low opacity could do the trick. This turned out to be a good idea, as it made the information more visible and appealing, so I pursued that avenue for the panel.
Dataset Summary
The dataset has been described in some previous posts, so I’ll just summarize the general data acquisition process and some of the improvements that have been done since. The original data looks as follows, where each row represents a song played at some point in time:
The Album Leaf,Into The Blue Again,Always For You,07 Jul 2022 22:25
Houndmouth,Good For You,Ride Or Die,07 Jul 2022 22:22
Blossoms,Cool LIke You,How Long Will This Last?,07 Jul 2022 22:22
The School,Loveless Unbeliever,I Want You Back,07 Jul 2022 22:19
Tennis,Cape Dory,Seafarer,07 Jul 2022 22:16
Caamp,Boys (Side B),Send the Fisherman,07 Jul 2022 21:59
Where each datapoint is stored in the order: Artist, Album, Song Name, Datetime; and the full dataset comprises of 180,000 datapoints.
Last.fm Cleaning Pipeline
Now, there’s some things to take care of on the full dataset like: filtering artists, standardizing datetimes, changing the names of artists for consistency, and removing duplicate entries (something that used to happen sometimes in the past with last.fm):
The Cure,Boys Don't Cry,Boys Don't Cry,2022-07-13 10:45:00-07:00
Better Than Ezra,Greatest Hits,Good,2022-07-13 10:42:00-07:00
Dinosaur Jr.,I Bet on Sky,Almost Fare,2022-07-13 10:37:00-07:00
Pulp,Different Class,Common People,2022-07-13 10:28:00-07:00
Courteeners,Falcon,The Opener,2022-07-13 10:22:00-07:00
The Smiths,Essentials,Panic,2022-07-13 10:20:00-07:00
After this step, I ended up with around 165,000 data entries.
Musicbrainz Artist Info Download
Although the information compiled on the last step would be enough for this application, I am downloading the artists’ data as follows:
Pulp,GB,Sheffield,76b2e842-5e85-4c97-ab62-d5bc315595b5,britpop,alternative rock,indie pop,53.3806626,-1.4702278,United Kingdom,England,Sheffield City Region,Sheffield,,
Queen,GB,London,0383dadf-2a4e-4d10-a46a-e9e041da8eb3,rock,hard rock,british,51.5073219,-0.1276474,United Kingdom,England,Greater London,London,,
R.E.M.,US,Athens,ea4dfa26-f633-4da6-a52a-f49ea4897b58,alternative rock,pop rock,rock,33.9597677,-83.376398,United States,Georgia,Athens-Clarke County,Athens-Clarke County Unified Government,,
RPA & The United Nations Of Sound,GB,,c6eb5beb-fd73-46dd-9f5a-5d36a26ab8a3,,,,54.7023545,-3.2765753,United Kingdom,,,,,
Ra Ra Riot,US,Syracuse,d8f63b51-73e0-4f65-8bd3-bcfe6892fb0e,indie rock,baroque pop,,43.0481221,-76.1474244,United States,New York,Onondaga County,City of Syracuse,,
Radiohead,GB,Abingdon-on-Thames,a74b1b7f-71a5-4011-9441-d0b5e4122711,alternative rock,art rock,rock,51.6714842,-1.2779715,United Kingdom,OX14 3UJ,England,South East England,Oxfordshire,Vale of White Horse
Ramones,US,New York,d6ed7887-a401-47a8-893c-34b967444d26,punk rock,pop punk,rock,40.7127281,-74.0060152,United States,New York,City of New York,,,
Where each row is an artist found in the data, and it’s information is stored as: Artist Name, Country Code, Region, Musicbrainz ID, Genre 1, Genre 2, Genre 3, Latitude, Longitude, Geo-info...
Amend Dataframe Names
Finally, one of the things I wanted to fix from the previous version was to amend the artists names in the dataset with the ones downloaded from Musicbrainz. To do this, I used the Levenshtein distance between the names of all the entries of the dataset, and the names present in the Musicbrainz parsed info as seen of this snippet of code:
artsMB = sorted(list(DTA_MBZ['Artist'].unique()))
replacements = {}
for art in arts:
dists = [levenshtein_distance(art.lower(), mbArt.lower()) for mbArt in artsMB]
replacements[artsMB[dists.index(min(dists))]] = {art}
DTA_CLN = aux.replace(DTA_CLN, replacements, ('Artist', 'Artist'))
CodeDev
The code for this project was not too complicated, although it did involve heavy tweaking of the parameters to get the looks right (specially the labels, line thicknesses and colors).
Time Info
To set the ranges of the plot, both the minimum and maximum dates were obtained from the dataset:
(to, tf) = (min(DTA_CLN['Date']), max(DTA_CLN['Date']))
daysTotal = (tf-to).days+1
Additionally, one of the things that had to be slightly changed was to that instead of using the datetime object of each entry in the dataset, it had to be converted to a timedelta one with an increment size of a day. This wasn’t too difficult, and was added into the dataframe as follows:
dteCpy = DTA_CLN['Date'].copy()
DTA_CLN['Interval'] = pd.to_datetime(dteCpy, errors='coerce', utc=True)
DTA_CLN['Interval'] = DTA_CLN['Interval'].dt.tz_localize(None).dt.to_period('D')
Counts Array
The original dataset is in a dataframe format, but as we will iterate through all artists and all intervals of time, it’s worth transforming everything into an array. We initialize our data structure in with a artistsNumber x daysRange size filled with zeroes as follows:
artists = list(A_TOP['Artist'])
countsArray = np.zeros([len(artists), daysTotal], dtype=np.uint16)
Where the artists list is sorted by frequency rank, so that they end up ordered in our visualization. With this in place, we can fill up our array by iterating by artist (row) and day (column):
for (ix, art) in enumerate(artists):
# Get all entries of the current artist
artSmple = DTA_CLN[DTA_CLN['Artist']==art]
# Get intervals at which songs were played and convert them to days
# (relative to the minimum date in the dataset)
playDates = list(artSmple['Interval'])
playDays = [
(datetime(i.year, i.month, i.day)-to.replace(tzinfo=None)).days
for i in playDates
]
# Count the frequencies of plays at each day
artCounts = dict(Counter(playDays))
# Replace the elements in our array with the artist ix, and day as column
for d in list(artCounts.keys()):
countsArray[ix, d] = artCounts[d]
This part was a bit confusing but, just to re-iterate: we simply took our dataframe intervals information and converted it to an array where each row is an artist, and each column represents the plays frequency at a given point in time (in days, relative to the min date of the dataset).
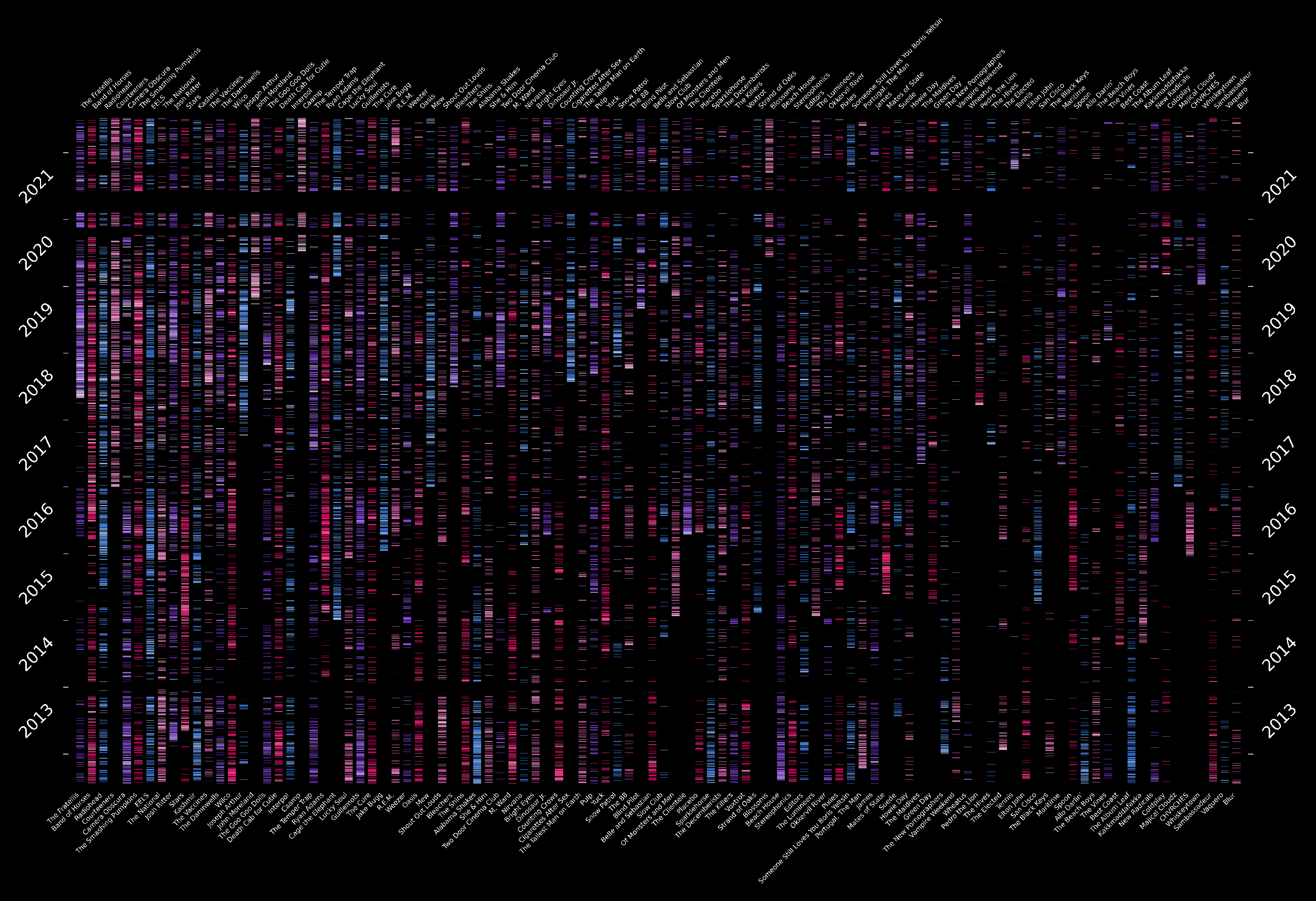
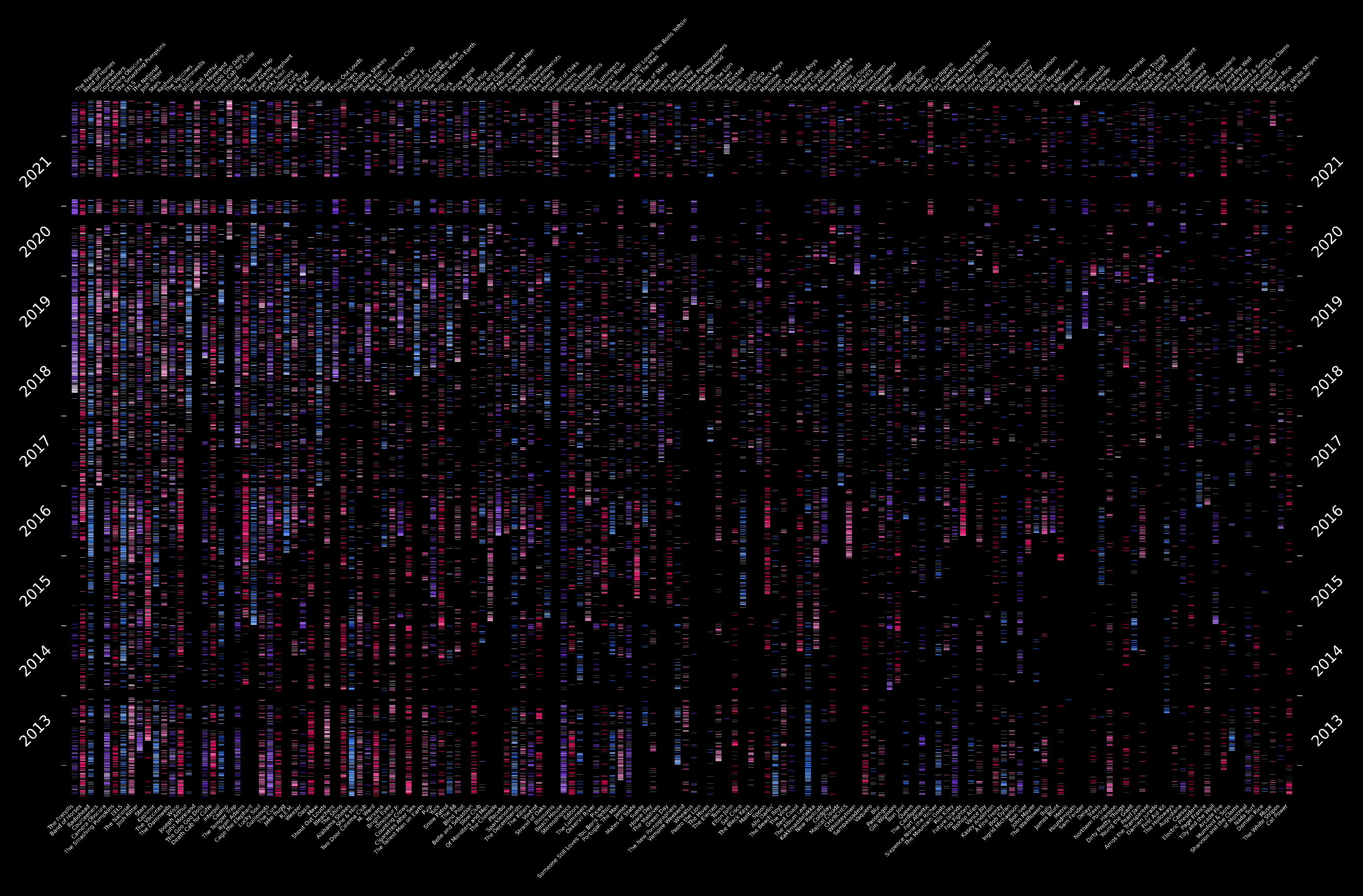
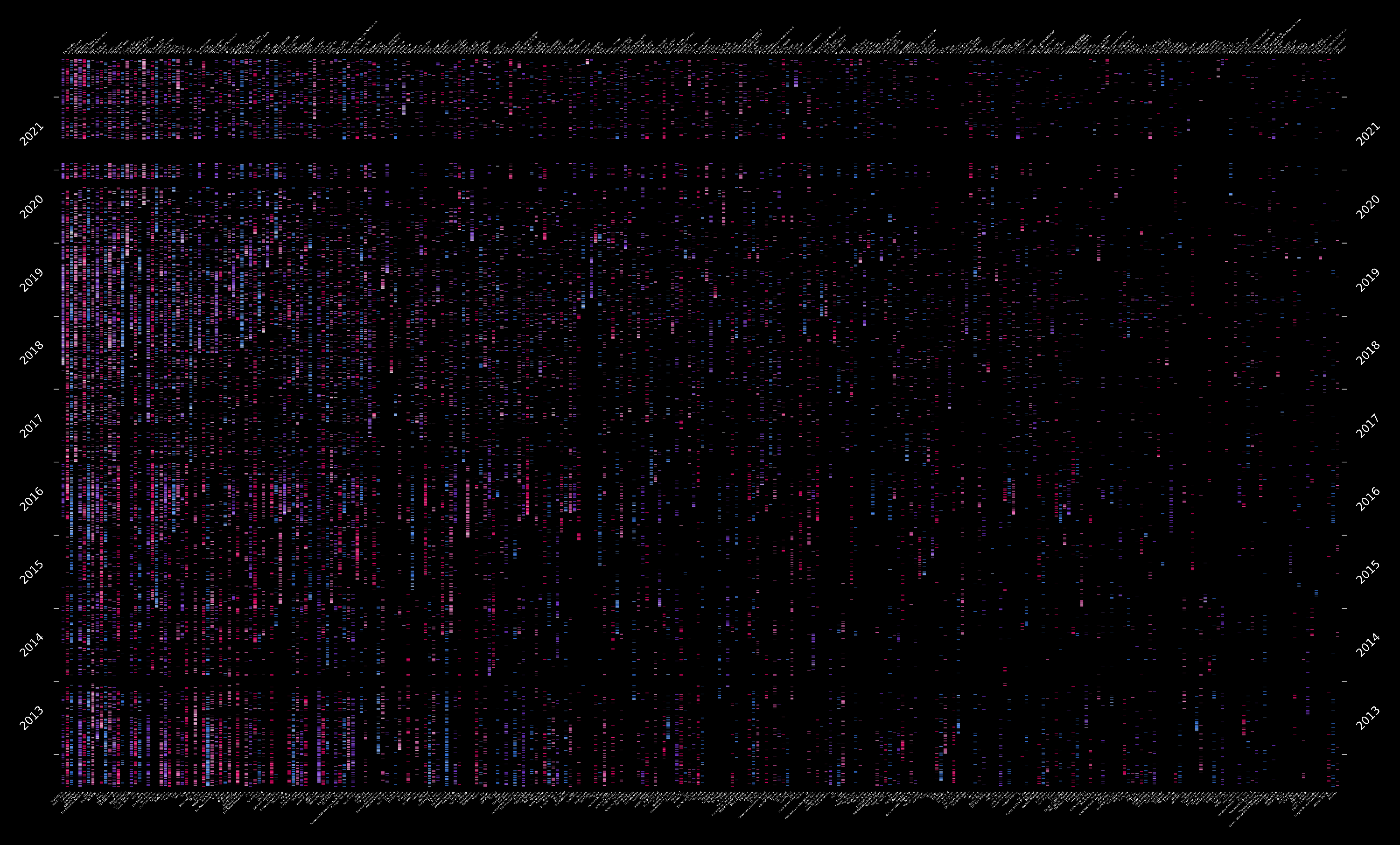
Strip Plot
Before actually plotting the counts, I decided to use a “wheel” of color maps so that the artists were distinguishable from one another. To do this, I created four cmap objects as follows:
SAT_CATS = ('#8338ecAA', '#ff006eAA', '#3a86ffAA', '#f15bb5AA')
MAPS = (aux.colorPaletteFromHexList([c, '#ffffff99']) for c in SAT_CATS)
norm = colors.LogNorm(vmin=1, vmax=50)
Where each one creates a gradient between the color (at its minimum), and white (at its maximum), and we create a log-normalizing function that ranges from 1 to 50 (mapping these values from 0 to 1) to make easy use of our cmaps. With this in place, we are ready to create our frequency strips. To do so, we iterate through artists and plot a line of a given color using the cmap object whenever one or more songs of each artist were played:
for (r, art) in enumerate(artists):
# Cycle through cmaps
clr = MAPS[r%len(MAPS)]
# For each day in our artist in which a song was played, plot a strip
for day in np.nonzero(countsArray[r])[0]:
ax.plot(
[r-.325, r+.325], [day, day],
color=clr(norm(countsArray[r][day])),
lw=.2, zorder=5
)
It is worth noting that we are inverting the row-column order (artists are columns in the plot, and rows are days) as it looks better in a wide display.
Labels and Axes
Now, for the more complicated part, labeling turned out to be somewhat of a pain to setup the artists names and years at the appropriate locations, with scaling that was proportional to the number of artists on display. I won’t go into much detail about these settings, but a function that was particularly useful for this application was np.interp, as shown:
artFontSize = np.interp(
TOP,
(50, 100, 250, 500, 600),
( 3, 3, 1, .25, .025)
)
yearFontSize = np.interp(
TOP,
(50, 250, 500),
( 8, 4.5, 4.5)
)
Finally, I decided to do a dark plot for this one, as it highlighted the colors better, removed all axes, and added some auxiliary lines on the sides to mark the beginnings and ends of the years.
Gallery
With the plots in place, we can take some notes on the results:
- Most of the data are fairly continuous temporally, except a period of about a couple of months in 2021 (which stands out as a black horizontal block across all artists). The explanation behind this data gap is that UC Berkeley got hacked, so I had to change all my passwords, one of them being my Last.fm one. Unfortunately, I forgot to update the login info in my computer, which I was using to listen to music all the time due to pandemic lockdowns.
- There’s some artist like Radiohead, Camera Obscura, or The Smashing Pumpkins that are rarely the highest played at any point in time, but are fairly constant throughouth; whereas some others like The Fratellis, Caamp, and John Moreland, are really concentrated at some points of the timeline.
- On a more personal level, this chart has given me the oportunity to backtrack on times at which I was going through changes or when I used to hang out with friends who would introduce me to new music; as it is easier to pinpoint those stages in my life according to the music I was listening to at those periods.

Code Repo
- Repository: Github repo
- Dependencies: matplotlib, pandas, numpy