A 3 day data-wrangling bootcamp that I designed for professors in my alma mater, Tecnológico de Monterrey.
Introduction
After the initial DataViz CADi I was hired to teach a data wrangling course using Python in a 3-day bootcamp. This time, instead of using Mathematica and R, we’d focus on the use of Python for common data-processing operations.
Objective
This course was designed to serve as an introduction to developing data-wrangling routines in Python. The bootcamp covered tools used in best-practices like virtual environments, and github; and also included exercises in the use of a wide array of libraries such as numpy, pandas, scikit-learn, beautifulsoup, OSMnx; amongst many others.
Select Exercises
Flights
This exercise used a public flights dataset to showcase common pandas data-frames operations such as: loading, filtering, aggregating, performing operations on subsets, etcetera.

Housing
A classic exercise on the California Housing dataset to teach the use of scikit-learn’s pipelines for data cleaning and wrangling.
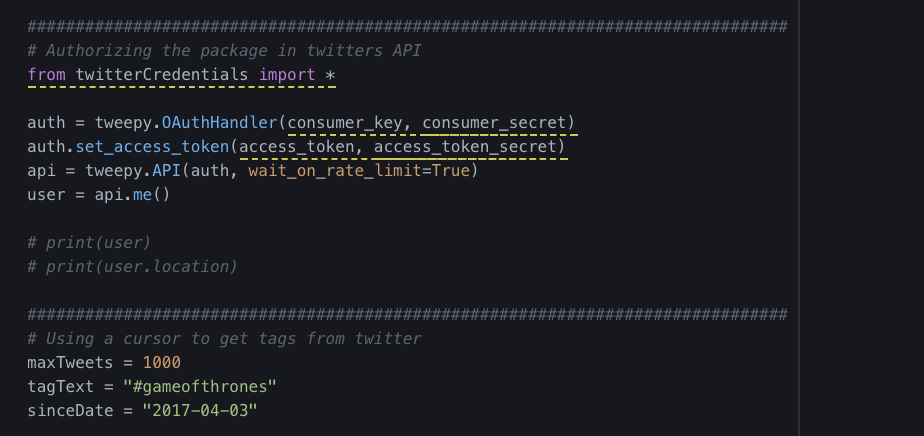
Twitter Topics Parser
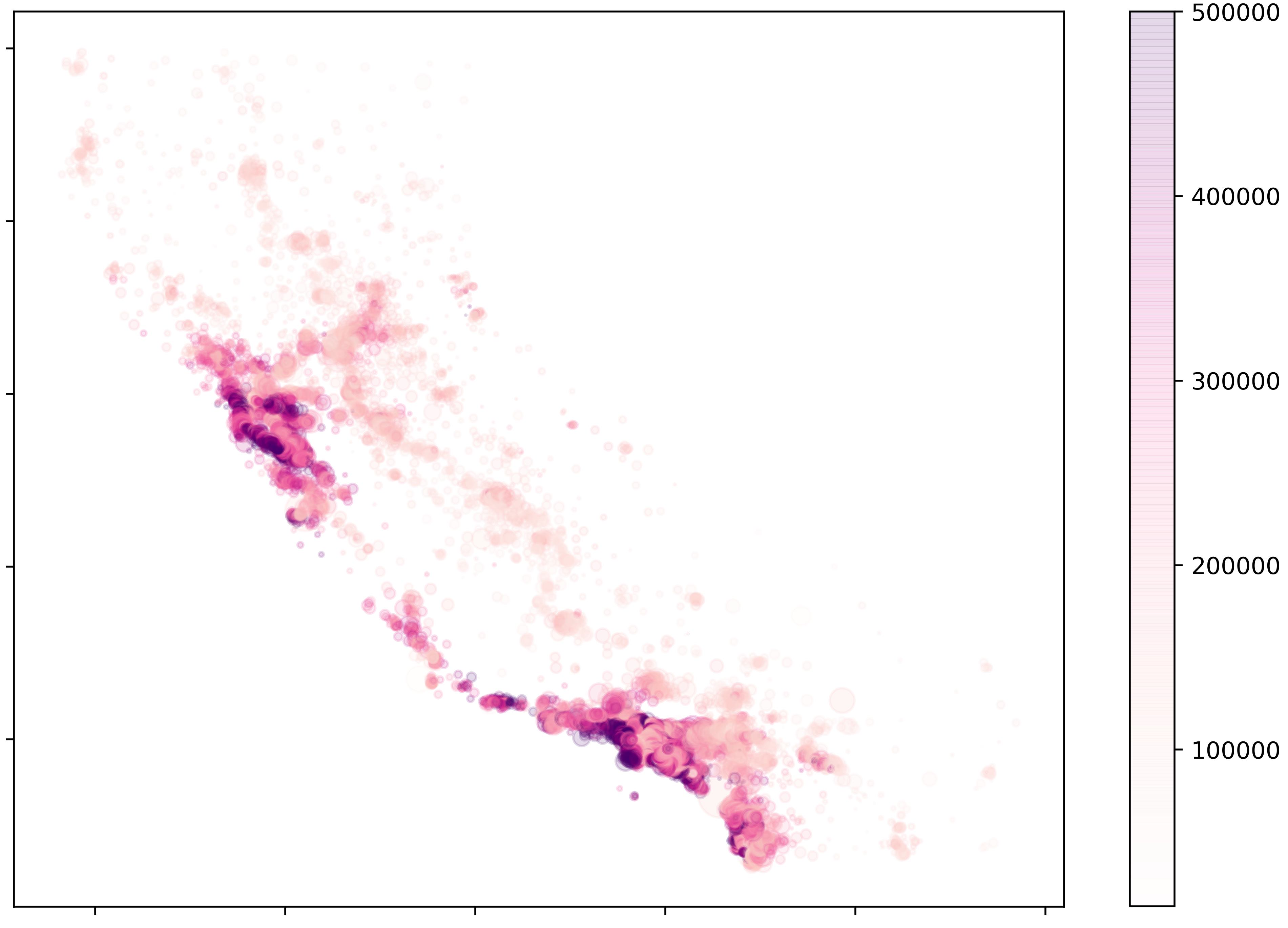
One of the data-scraping exercises. We parsed Twitter for hashstags for further analysis (such as sentiment analysis).
Topics and Code
And here’s a full list of the topics and exercises covered in the bootcamp (with links to their scripts):
- Intro and Basics
- Data Wrangling
- Data Sources:
- Scraping: beautifulsoup
- Google Trends: pytrends, “how to breakup”, CRISPR
- Twitter: twitter-tools, tweepy, spaCy, sentiment analysis, “1984” tokens, tweets sentiment analysis
- GeoData: “Game of Thrones”, OSMnx, OSMnx Networks, OSMnx Buildings
- Dropbox: backup files
- RSS and XML: RSS feed, iTunes playlist parser
- Data Thoughts: dataViz, storytelling
With the whole sitemap available in the following link.
Code repo
- Repository: Github repo with all the materials and exercises