Following up the clustering post, we now batch-process our images, and wrap up the palettes in a pypi package.
The first part of this work dealt with identifying the dominant colors in artwork, but it still neded some work in order to generate the batch processing of the palettes to ship them in a pypi package.

Intro
Having coded our dominant color identifier, we want to auto-process our artworks and export their palettes to a database for sharing in a pypi package. I want users to be able to use this package’s color palettes by simply loading them by their hash ids. To be able to do this in a simple way, we need to share the serialized databases through pypi and to provide with a way to easily browse the palettes in its github repo.
CodeDev
This time, the code will focus more on automating calls to our clustering script and making sure that we handle our palettes databases in consistent ways that allow us to share our results in our pypi project.
Batch-Processing
Let’s get started with the automated processing of the artworks and their storage in our databases.
Swatches Databases
To keep things as simple as possible I decided to store the palettes data in two structures:
- A dictionary relating the hashed palette
IDto the list of colors available in the palette (serialized). - A dataframe containing
artist, title, palette, hash, clusters, clustering, url, filenamefor each artwork (serialized and CSV).
The process I decided to follow for each entry of these databases was:
* Load the database file
* Identify dominant colors
* Generate artwork entry
* Concatenate the entry to the database and drop duplicates if needed
* Export database to disk
Where the palette’s ID is created by generating the sha256 from the concatenation of the palette’s artist name and artwork title, and is stored in the hash column of the dataframe.
As an example of our final products within our package, we can load our databases in dictionary and dataframe forms:
art.SWATCHES
# out: {
# 'F19A02C5AA8F65DA3176': ['#C83D79', '#409D3B', '#2BDCED'],
# '3769567070AAA69B81BB': ['#C93457', '#048188', '#890B5D'],
# 'F2B84BF71514048816BE': ['#DA3781', '#ED9408', '#A577FF'],
# ...
# '25BBF1562A1460CB411C': ['#533F3B', '#E7B578', '#B67647', '#17769F'],
# '411E440EB49799EDC6CD': ['#0A0F10', '#232C39', '#BB8673', '#93483C'],
# 'A2FFF99903488BB868BB': ['#D0D2CF', '#3D741D', '#2F96C8'],
# 'A38A57C34AA94A04F01F': ['#F1E6EC',
#}
art.SWATCHES_DF
# out:
# artist title palette hash clusters clustering url filename
# 0 Disney "Aladdin 01" #F1E6EC,#F8A448,#B2364E,#21347C,#5499DA A38A57C34AA94A04F01F 5 AgglomerativeClustering https://filmartgallery.com/products/aladdin-1 183464.png
# 1 Disney "The Lion King 01" #F77A1D,#D90013,#8D2928 B104452E111977890AB5 3 AgglomerativeClustering https://filmartgallery.com/products/the-lion-king 183465.png
# 2 Disney "The Lion King 02" #273547,#737467,#A7B0AB,#265688 1EB115912963DD4E98E5 4 AgglomerativeClustering https://filmartgallery.com/products/the-lion-k... 183466.png
# 3 EdnaAndrade "Atom Cloud" #734950,#4B8182,#A79D96,#DAD1C5,#AF6D64 B8E300333DB2EAD2E3CF 5 AgglomerativeClustering https://www.wikiart.org/en/edna-andrade/atom-c... 183442.png
# 4 EdnaAndrade "Cross" #8B7F68,#A7A197,#ECE4E0,#E2CE96,#BA9940 B5758312CDE71EDD91C2 5 AgglomerativeClustering https://www.wikiart.org/en/edna-andrade/cross-... 183441.png
...
We will go through how to generate these objects in the rest of this post!
Processing
To be able to process a large number of artworks, their information is manually stored in CSV files where the filename is the name of the artist. After some thought, I had the content of these files look as follows:
6,183425.png,"Improvisation 31 (Sea Battle)",https://www.nga.gov/collection/art-object-page.56670.html
...
5,183427.png,"Landscape with Figures and a Crucifix", https://www.nga.gov/collection/art-object-page.90725.html
Where the first entry is the number of clusters, the second one is the filename, the third one is the title, and the final one is the URL where the artwork can be found. In this standardized way we can store the information of all the artists we want to analyze for palettes. Once we have our files, we can iterate through their entries by running the following bash script with its argument being the name of the artist as it appears in the CSV filename:
ARTIST=$1
###############################################################################
# Path Constants
###############################################################################
DATA_PATH="$HOME/Documents/GitHub/ArtSciColor/ArtSciColor/data"
ITER_FILE="${DATA_PATH}/${ARTIST}.csv"
PTH_I="${DATA_PATH}/sources/${ARTIST}/in/"
PTH_O="${DATA_PATH}/sources/${ARTIST}/out/"
###############################################################################
# Paintings Iterator
###############################################################################
while IFS=, read -r CNUM FNAME TITLE LINK; do
outputString=$(
python "$(dirname "$0")/fprintPainting.py" \
"${PTH_I}" \ # Input path
"${PTH_O}" \ # Output path
"${FNAME}" \ # Artwork filename
"${CNUM}" \ # Number of clusters to identify
"${LINK}" \ # Artwork URL reference
"${ARTIST}" \ # Artist's name
"${TITLE}" # Artwork title
)
done < $ITER_FILE
Which initially sets up the paths where we can find the CSV file with our artworks information ITER_FILE, the path where the input images will be located PTH_I, and the path in which the outputs will be exported PTH_O (it’s important to note that neither the input or output images are shared as part of the package, just processed and exported for analysis). The second part of the script goes through each line of the file and separates the entries by commas so that the filename, number of clusters, URL, and title can be passed to the python fingerPrint.py script. This script is where all the magic described in the original post takes place and, additionally, appends the information of the currently-processed in the its final lines:
db = art.loadDatabase(DB_FILE)
newEntry = pd.DataFrame({
'artist': ARTIST,
'title': TITLE,
'palette': ','.join([c.hex.upper() for c in swatchHex]),
'clusters': CLST_NUM,
'clustering': str(CLUSTERING['algorithm'].__name__),
'filename': FILENAME,
'hash': hashName,
'url': URL
}, index=[0])
db = pd.concat([db.loc[:], newEntry]).reset_index(drop=True).drop_duplicates()
art.dumpDatabase(db, DB_FILE)
art.exportDatabase(db, DF_FILE)
This makes sure that every entry of our artworks gets added both to the serialized and CSV versions of the complete database (please have a look at the first part of this series, and the script for more information on how the clustering takes place). This way, we can process all of our files in an automated way and move on to generating our HTML/MD galleries.
Exporting MD/HTML
Let’s get started on auto-generating our README files so that we can have a gallery for our color palettes.
Part of automating these scripts has the objective of making adding new palettes as streamlined as possible, which involves generating files that make it easy to access and explore available swatches. I will eventually generate some reasonable documentation for the package but in the meantime I decided to generate some simple HTML and Markdown files so that every time I updated the database they were updated in the github repository. Each artist has its own MD file generated as follows:
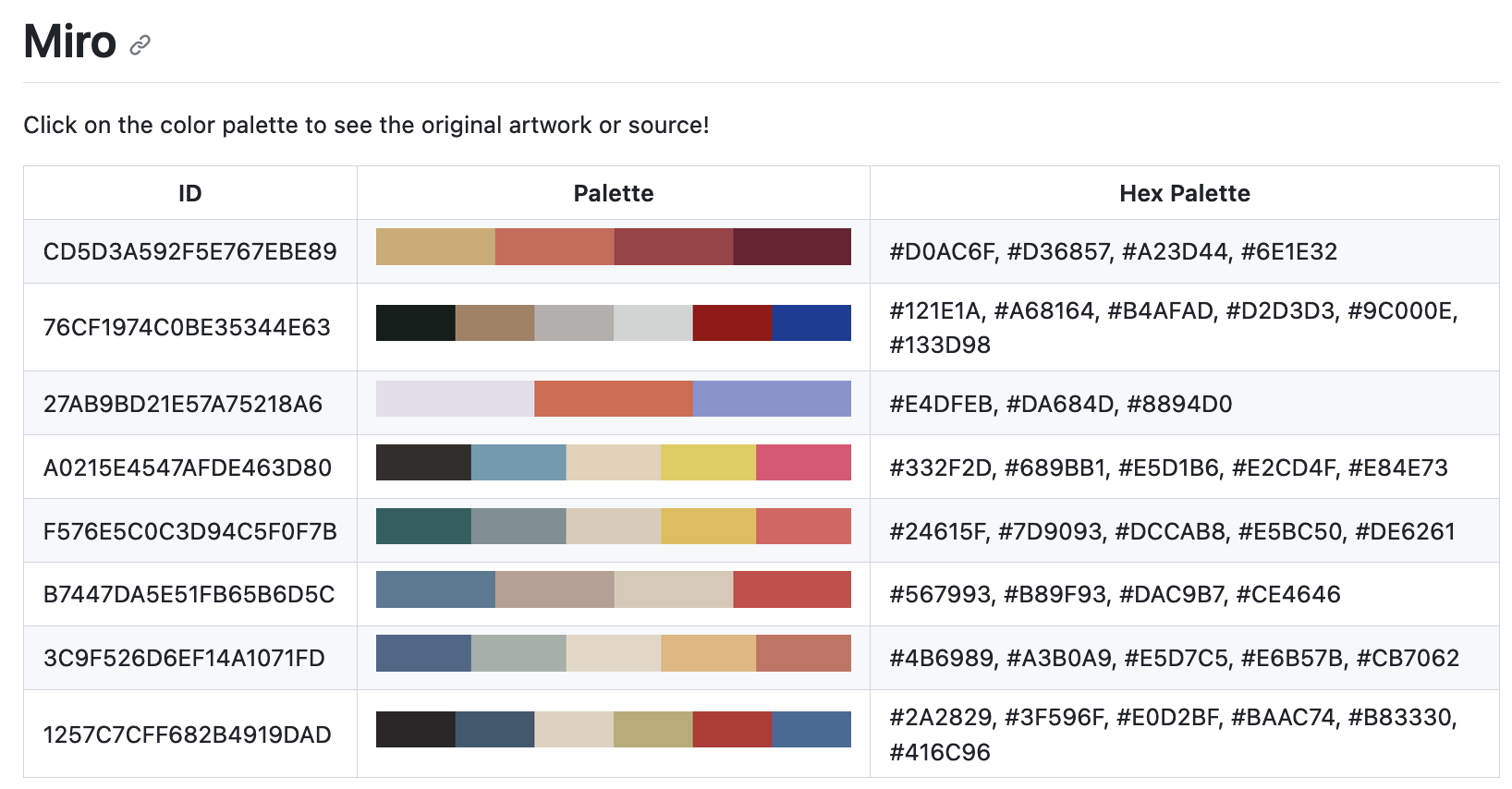
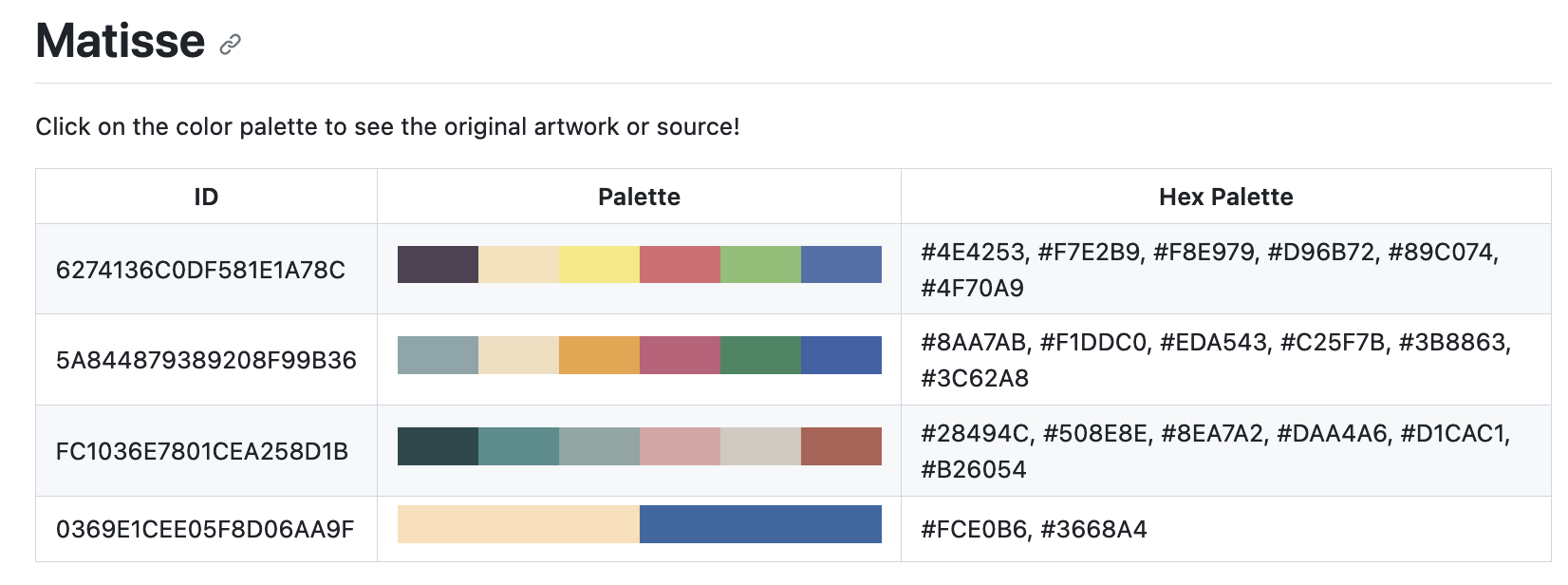
Where clicking the color swatch image takes the user to the original artwork. To automate this, we define some string templates for the HTML headers and entries:
hdr = ('Title', 'ID', 'Palette', 'Hex Palette')
RDM_HEADER = [
f'<th style="text-align: center; vertical-align: middle;">{e}</th>'
for e in hdr
]
RDM_TEXT = '''
<!DOCTYPE html>
<html><body>
<h1>{}</h1>
<p>Click on the color palette to see the original artwork or source!</p>
<table style="width:100%">
<tr>{}</tr>{}
</table>
</body></html>
'''
def generateHTMLEntry(artist, url, title, relPth, hname, strPal):
entry = [
f'<td style="text-align: center; vertical-align: middle;">{e}</td>'
for e in (
f'<a href={url} style="font-size:14px">{title}</a>',
f'<p style="font-size:14px">{hname}</p>',
f'<a href={url} style="font-size:14px"><img style="border-radius: 14px;" src="{relPth}" height="25"></a>',
f'<p style="font-size:14px">{strPal}</p>'
)
]
mdRow = '\r<tr>'+' '.join(entry)+'</tr>'
return mdRow
Once this is in place, we can iterate through our database as follows:
db = art.loadDatabase(DB_FILE)
hexSwatches = art.loadDatabase(PATH_SWT, df=False)
###############################################################################
# Export swatches and generate MD text
###############################################################################
mdTexts = []
for (ix, entry) in db.iterrows():
(hname, artist, title, url) = [
entry[c] for c in ('hash', 'artist', 'title', 'url')
]
# Get swatch --------------------------------------------------------------
pal = entry['palette'].split(',')
strPal = art.listPalToStr(pal)
hexSwt = [Color(h) for h in pal]
# Generate swatch img -----------------------------------------------------
swatch = art.genColorSwatch(width, height, hexSwt)
swtchImg = Image.fromarray(swatch.astype('uint8'), 'RGB')
# Add swatch to hash database ---------------------------------------------
hexSwatches[hname] = pal
# Generate table html entry -----------------------------------------------
palPth = join(PATH_OUT, f'{hname}.png')
relPth = join('../media/swatches', f'{hname}.png')
swtchImg.save(palPth)
mdRow = art.generateHTMLEntry(artist, url, title, relPth, hname, strPal)
mdTexts.append(mdRow)
where the loop will export the png with the color swatch, and generate the HTML row for each artwork. Once we go through the whole database, we can export the HTML and markdown files to disk:
###############################################################################
# Export HTML/MD data
###############################################################################
text = art.RDM_TEXT.format(ARTIST, ''.join(art.RDM_HEADER), ''.join(mdTexts))
# Write to disk ---------------------------------------------------------------
with open(join(PATH_RDM, f'{ARTIST}.md'), 'w') as f:
f.write(text)
with open(join(PATH_RDM, f'{ARTIST}.html'), 'w') as f:
f.write(text)
Shipping Data
By default, python packages do not automatically ship with data to pypi. To do this, our setup.py file needs the package_data argument with the reference to the files to be installend along with the codebase:
setuptools.setup(
...
package_data={
'ArtSciColor': ['./data/DB.bz', './data/DB.csv', './data/SWATCHES.bz']
}
)
Now, the database will be installed with the package, but it won’t be loaded when when the package is imported. To implement this behavior, we need to add the following lines to the constants.py file:
DATA_PATH = pkg_resources.resource_filename('ArtSciColor', 'data/')
(PT_SW, PT_DF) = (join(DATA_PATH, 'SWATCHES.bz'), join(DATA_PATH, 'DB.csv'))
try:
SWATCHES = aux.loadDatabase(PT_SW, df=False)
SWATCHES_DF = pd.read_csv(PT_DF)
except:
warnings.warn("Missing colors database!")
Where the pkg_resources.resource_filename command returns the resources path for our package, so we try to load the datasets and return a warning if these files are not found.
Use, and FutureDev
Let’s see how we can load our color palettes. After installing the package with:
pip install ArtSciColor
Now, we will be loading one of Signac’s palettes:

So we import our library and load the palette as follows with its hash ID:
import ArtSciColor as art
art.getSwatch('68C21FD74061C3E7659C')
# out: ['#845E48', '#A39D7F', '#D8CCA4', '#FFD860', '#F8B061', '#D9784E']
And that’s it! We’re ready to use it in our matplotlib applications as we need! We can use any of the palettes readily available in our README files on the projects repo!
In the near future, I’ll be adding more capabilities to the package, like generating cmaps, converting between color-spaces, and more utilities useful in scientific data visualization.
Code Repo
- Repository and pypi: Github Repo, pypi package
- Dependencies: matplotlib, pandas, numpy, opencv, scikit-learn, Pillow, colour, colorir, compress-pickle